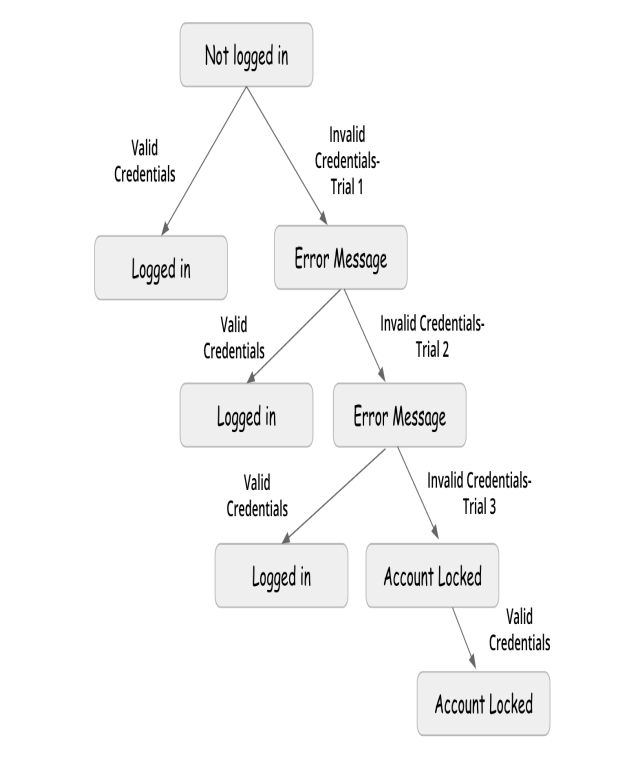
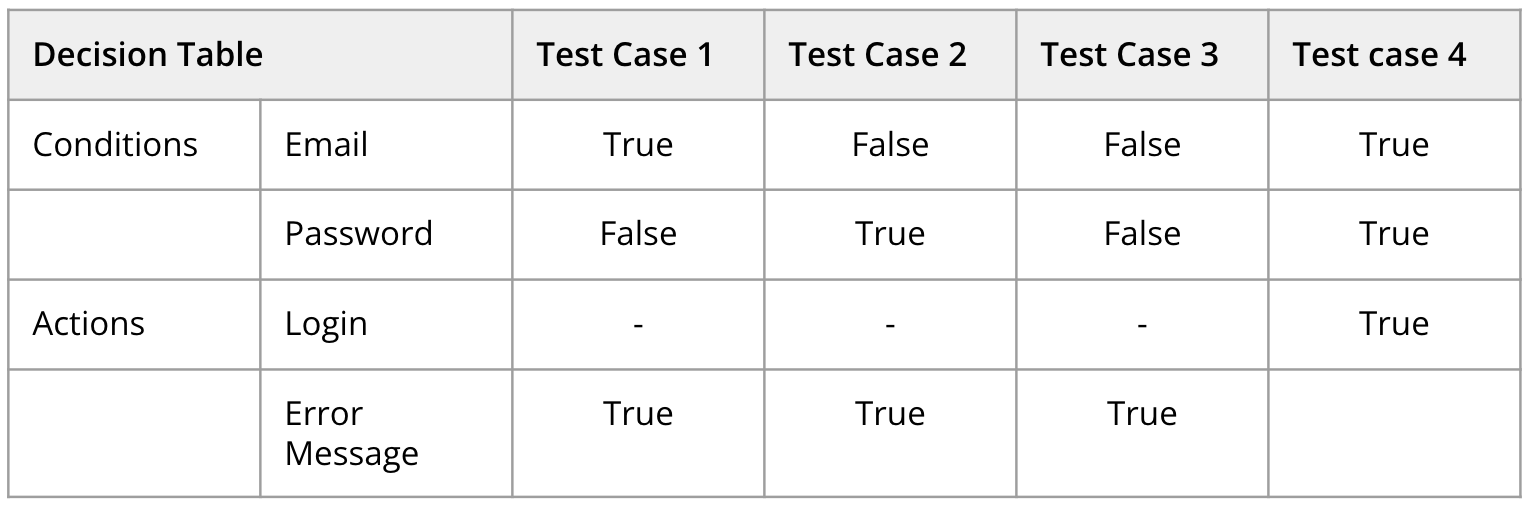
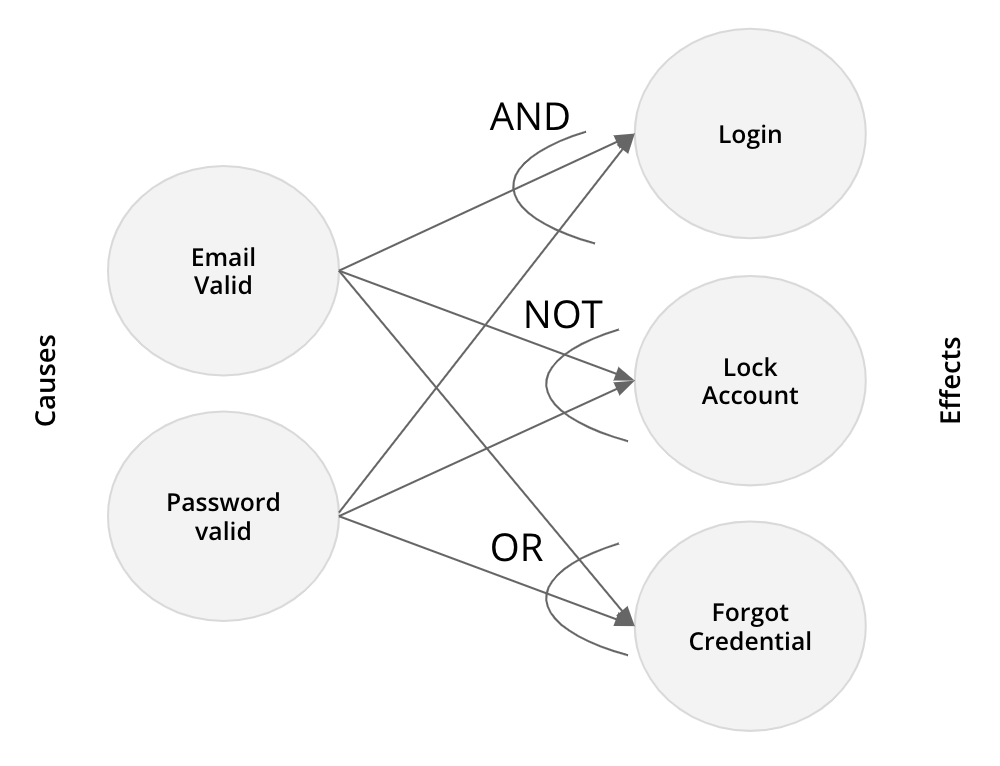
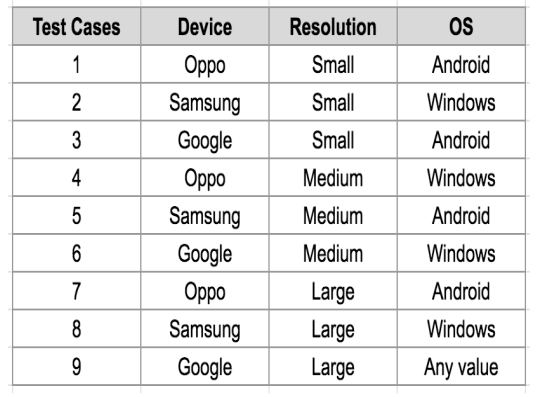
English
- English
- Afrikaans
- Gjuha shqipe
- العربية
- Հայերեն
- Азәрбајҹан дили
- Euskara
- беларуская мова
- български език
- Català
- Chinese (Simplified)
- Chinese (Traditional)
- Српскохрватски језик
- čeština
- Danmark
- Nederlands
- eesti keel
- Filipino
- Finnish
- Français
- Deutsch
- Ελληνικά
- magyar
- Indonesia
- Irish
- Italiano
- にほんご
- 한국어
- lietuvių kalba
- Malay
- norsk
- Polski
- Português
- limba română
- Русский
- Español
- Swedish
- ภาษาไทย
- Turkish
- українська мова
Appearance